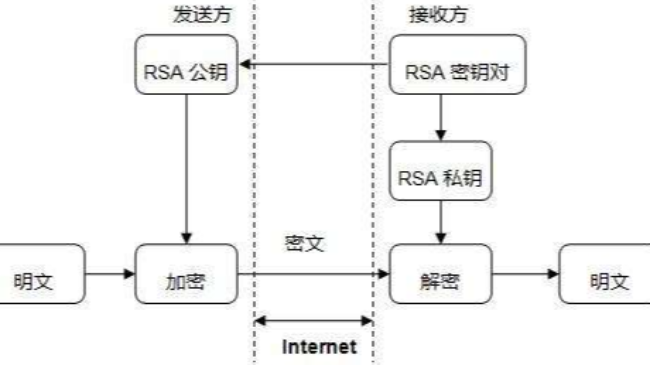
RSA加密算法是一种非对称加密算法。在公开密钥加密和电子商业中RSA被广泛使用。RSA是1977年由罗纳德·李维斯特(Ron Rivest)、阿迪·萨莫尔(Adi Shamir)和伦纳德·阿德曼(Leonard Adleman)一起提出的。当时他们三人都在麻省理工学院工作。RSA就是他们三人姓氏开头...

游程编码(RLE,run-length encoding),又译行程长度编码,又称变动长度编码法(run coding),在控制论中对于二值图像而言是一种编码方法,对连续的黑、白像素数(游程)以不同的码字进行编码。游程编码是一种简单的非破坏性资料压缩法,其好处是加压缩和解压缩都非常快。其方法是计算连...
最近,在del.icio.us mailinglist(译者按:应该是美味书签的讨论版块。以下del.icio.us翻译为美味书签)上面发了一个问题:“有人知道美味书签的数据库设计吗?”。之后我得到了一些回复,所以我想把这部分东西的知识分享给大家。 疑问 当你要为一个书签添加你认为需要的一个或多个标...
1. 问题描述在大规模数据处理中,常遇到的一类问题是,在海量数据中找出出现频率最高的前K个数,或者从海量数据中找出最大的前K个数,这类问题通常称为“top K”问题,如:在搜索引擎中,统计搜索最热门的10个查询词;在歌曲库中统计下载率最高的前10首歌等等。2. 当前解决方案针对top k类问题,通常...
在段式虚拟存储器中,虚存空间中能容纳的程序段数要比主存空间中能存放的相同长度的程序段数多得多。因此,必然会出现当主存中所有页面都已经被占用,或者所有主存空间都已经被占用,而又要从磁盘存储器中调入新页的情况。这时,必须从主存储器中淘汰掉一个不常用的页面,以便腾出主存空间来存放新调入的页面。下面介绍几种...
创建型模式 1、FACTORY—追MM少不了请吃饭了,麦当劳的鸡翅和肯德基的鸡翅都是MM爱吃的东西,虽然口味有所不同,但不管你带MM去麦当劳或肯德基,只管向服务员说“来四个鸡翅”就行了。麦当劳和肯德基就是生产鸡翅的Factory 工厂...
一群猴子排成一圈,按1,2,...,n依次编号。 然后从第1只开始数,数到第m只,把它踢出圈, 从它后面再开始数, 再数到第m只,在把它踢出去..., 如此不停的进行下去, 直到最后只剩下一只猴子为止,那只猴子就叫做大王。 要求编程模拟此过程,输入m...
折半查找法也称为二分查找法,它充分利用了元素间的次序关系,采用分治策略,可在最坏的情况下用O(log n)完成搜索任务。 【基本思想】 将n个元素分成个数大致相同的两半,取a[n/2]与欲查找的x作比较,如果x=a[n/2]则找到x,算法终止。如果x<a[n/2]...

smarteng
人生就流星,虽然转瞬即逝,但也有永恒。
- 使用Erlang的OTP框架创建应用
- php 使用curl模拟登录discuz以及模拟发帖
- 腾讯QQ、阿里旺旺、淘宝、MSN在线状态代码生成
- 新浪微博错误代码解析
- erlang程序设计笔记
- 《HTML 5与CSS 3权威指南》权威的HTML5与CSS3实战教程
- dedecms修改数据库密码配置文件
- 服务器优化小记--Etag和Expires
- Mediawiki的配置和修改方法
- 在PHP5中使用PHPMailer发送邮件
- PHP中冒号、endif、endwhile、endfor介绍
- PHP框架——ThinkPHP
- 使用Golang的官方mock工具--gomock、mockgen
- QQ登陆成功返回openId后与网站绑定
- MacOs 电脑关闭/打开IPV6
- MacOs 电脑关闭/打开IPV6
- MySQL中datetime和timestamp的区别
- C++声明结构
- 如何保证数据库和缓存的一致性
- 优雅的golang日期时间处理库go-carbon
- API接口纪要
- 解析 Golang 测试(11)- 模糊测试
- 解析 Golang 测试(10)- 什么是好的单测
- 解析 Golang 测试(9)- 一篇文章搞懂 testify
- 解析 Golang 测试(8)- gomonkey 实战
- 解析 Golang 测试(7)- 如何针对 Redis 进行 Fake 测试
- 解析 Golang 测试(6)- 如何针对 MySQL 进行 Fake 测试
- 解析 Golang 测试(5)- MySQL 经典 mock driver—— sqlmock
- 解析 Golang 测试(4)- 一篇文章教你分清 Mock,Stub,Fake
- 解析 Golang 测试(3)- goconvey 实战
- 2023年11月(1)
- 2023年10月(1)
- 2023年3月(2)
- 2023年2月(1)
- 2022年12月(1)
- 2022年9月(13)
- 2022年8月(5)
- 2022年7月(9)
- 2022年6月(2)
- 2022年5月(2)
- 2022年4月(1)
- 2022年3月(2)
- 2021年12月(1)
- 2021年11月(14)
- 2021年10月(2)
- 2021年9月(111)
- 2015年3月(1)
- 2014年5月(4)
- 2014年4月(18)
- 2014年1月(1)
- 2013年11月(2)
- 2013年7月(1)
- 2013年6月(1)
- 2013年3月(13)
- 2013年2月(3)
- 2013年1月(1)
- 2012年12月(8)
- 2012年11月(8)
- 2012年10月(1)
- 2012年9月(13)
- 2012年8月(4)
- 2012年6月(2)
- 2012年5月(10)
- 2012年4月(13)
- 2012年3月(9)
- 2012年2月(8)
- 2011年11月(1)
- 2011年8月(9)
- 2011年7月(8)
- 2011年6月(8)
- 2011年5月(7)
- 2011年4月(19)
- 2011年3月(15)
- 2011年2月(8)
- 2011年1月(9)
- 2010年12月(2)
- 2010年11月(2)
- 2010年10月(2)
- 2010年9月(8)
- 2010年8月(9)
- 2010年7月(1)
- 2010年6月(9)
- 2010年5月(5)
- 2010年1月(7)
- 2009年12月(21)
- 2009年11月(29)
- 2009年10月(100)
- 2009年8月(1)
- 2009年7月(15)
- 2009年6月(52)