Bleve代码阅读(二)——Index Mapping
时间:2022-8-1 作者:smarteng 分类: Go语言
引言
Bleve是Golang实现的一个全文检索库,类似Lucene之于Java。在这里通过阅读其代码,来学习如何使用及定制检索功能。也是为了通过阅读代码,学习在具体环境下Golang的一些使用方式。代码的路径在github上https://github.com/blevesearch/bleve。
Index Mapping是bleve的一个功能特性,用来控制每个类型的文档,文档内的每个字段,具体应该如何被分析、索引、存储,这部分与Lucence的设计思路相同。
1 IndexMapping的结构
Bleve通过IndexMapping及各成员结构,来控制如何对每种类型的Document,Document内的NestDocument,Document内的各Field进行分析、索引和存储。它本身是一个递归的结构,在DocumentMapping这一层可以进行任意深度的嵌套。
我们先整体看一下Index Mapping及其成员的从属关系。下图是我画的结构简图,很多成员并未在图上体现出来。本节的内容就是从左到右依次介绍每个结构类型的及其成员对应的物理意义。
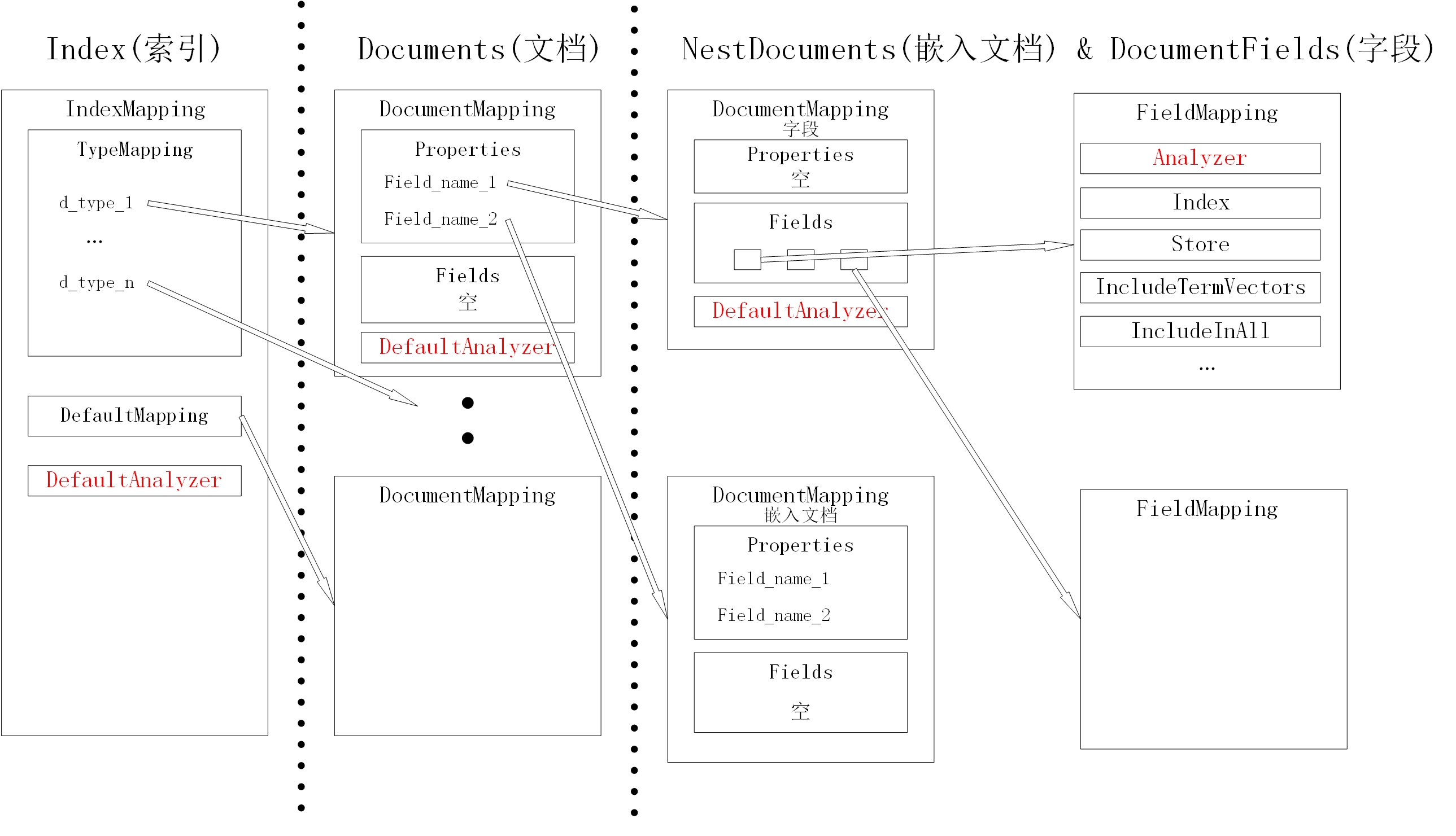
1.1 IndexMapping
从上一篇文章Bleve代码阅读(一)——新建索引我们知道,新建一个索引首先需要初始化一个IndexMapping结构。在示例代码中,这是通过函数bleve.NewIndexMapping()实现的,然后这个结构的指针被作为参数传递给bleve.New(index_path, index_mapping)。我们还知道,这个结构的内容被序列化后,存储在index文件里了。因此,这个结构与索引是一一对应的。
下面我们先看一下IndexMapping的定义代码,这个结构在上一篇文章也给出了。
type IndexMappingImpl struct {
TypeMapping map[string]*DocumentMapping `json:"types,omitempty"`
DefaultMapping *DocumentMapping `json:"default_mapping"`
TypeField string `json:"type_field"`
DefaultType string `json:"default_type"`
DefaultAnalyzer string `json:"default_analyzer"`
DefaultDateTimeParser string `json:"default_datetime_parser"`
DefaultField string `json:"default_field"`
StoreDynamic bool `json:"store_dynamic"`
IndexDynamic bool `json:"index_dynamic"`
DocValuesDynamic bool `json:"docvalues_dynamic,omitempty"`
CustomAnalysis *customAnalysis `json:"analysis,omitempty"`
cache *registry.Cache
}上图最左边的矩形,就是代表了IndexMappingImpl这个结构,下面都以IndexMapping这个名称代替。TypeMapping也与图中的同名矩形对应,它是IndexMapping的一个成员。我们这里重点看一下这四个成员:
- TypeMapping:它是一个字符串到DocumentMapping指针的map。它的key是字符串,代表Document的类型。它的value是DocumentMapping的指针,用来定制该类型文档的索引方式。
- DefaultMapping:它是DocumentMapping的指针。当TypeMapping没有配置某类型文档的DocumentMapping时,则该类文档使用该默认的DocumentMapping。
- DefaultAnalyzer:默认的根节点Analyzer。由于每个DocumentMapping、每个DocumentField都可以配置自己的Analyzer,当处理某个Field时,优先使用最个性化的设置。找不到个性化的才使用默认的,一级一级往上找,直到这里。
- DefaultType:当一篇文档未提供分类时,就会使用DefaultType设置的类型名称,默认是“_default”,也可以修改。需要注意的是,一个文档时DefaultType不等于它就要使用DefaultMapping,可以在TypeMapping中为DefaultType设置个性化的索引方式。
1.2 DocumentMapping
从本文开头的图中可以看出,DocumentMapping是最多出现的一个结构,在文档、嵌入文档、字段这几个概念层次上都要用到。任何一个文本结构,都应该对应一个DocumentMapping,文本结构包括整个文档、文档内的嵌入文档、文档或嵌入文档内的字段。DocumentMapping的定义如下:
type DocumentMapping struct {
Enabled bool `json:"enabled"`
Dynamic bool `json:"dynamic"`
Properties map[string]*DocumentMapping `json:"properties,omitempty"`
Fields []*FieldMapping `json:"fields,omitempty"`
DefaultAnalyzer string `json:"default_analyzer,omitempty"`
// StructTagKey overrides "json" when looking for field names in struct tags
StructTagKey string `json:"struct_tag_key,omitempty"`
}1.2.1 文档
图中第二列最顶端的矩形,是一个对应原始文档的DocumentMapping。我们在这里重点关注以下几个成员:
- Enabled:如果为False,则整个文本结构不被index处理。
- Properties:一个map。key为文档的成员名,value是一个DocumentMapping的指针,该DocumentMapping对定义该成员的文本应该被如何处理。无论该成员是一个嵌入文档或是一个字段,都需要一个DocumentMapping与之对应。
- Fields:一个FieldMapping指针的切片。作为DocumentMapping的成员,如果当前DocumentMapping对应于一个文档或嵌入文档,则该字段为空。只有当前DocumentMapping对应一个字段,该成员才有可能非空。每个FieldMapping用来控制该字段应该被索引怎样分析、存储,一个字段可以有多个分析、存储方式。
- DefaultAnalyzer:当前文本结构的默认Analyzer。
1.2.2 嵌入文档
图中第三列下面的矩形,是一个对应嵌入文档的DocumentMapping。它所有成员的意义与对应文档的DocumentMapping相同。
1.2.3 字段
图中第三列顶端的矩形,是一个对应字段的DocumentMapping。它的成员的意义与对应文档的DocumentMapping略有不同,体现在以下两方面:
- Properties:当它是一个对应字段的DocumentMapping的成员时,为空。
- Fields:当它是一个对应字段的DocumentMapping的成员时,才可以不为空。它是一个FieldMapping指针的切片,定义了该字段应该被怎样处理,可以有多个处理方式。
1.3 FieldMapping
FieldMapping描述了一个具体的字段如何被放入索引。它一定包含于一个对应字段DocumentMapping,而不能直接被对应文档的DocumentMapping包含。FieldMapping的定义如下:
type FieldMapping struct {
Name string `json:"name,omitempty"`
Type string `json:"type,omitempty"`
// Analyzer specifies the name of the analyzer to use for this field. If
// Analyzer is empty, traverse the DocumentMapping tree toward the root and
// pick the first non-empty DefaultAnalyzer found. If there is none, use
// the IndexMapping.DefaultAnalyzer.
Analyzer string `json:"analyzer,omitempty"`
// Store indicates whether to store field values in the index. Stored
// values can be retrieved from search results using SearchRequest.Fields.
Store bool `json:"store,omitempty"`
Index bool `json:"index,omitempty"`
// IncludeTermVectors, if true, makes terms occurrences to be recorded for
// this field. It includes the term position within the terms sequence and
// the term offsets in the source document field. Term vectors are required
// to perform phrase queries or terms highlighting in source documents.
IncludeTermVectors bool `json:"include_term_vectors,omitempty"`
IncludeInAll bool `json:"include_in_all,omitempty"`
DateFormat string `json:"date_format,omitempty"`
// DocValues, if true makes the index uninverting possible for this field
// It is useful for faceting and sorting queries.
DocValues bool `json:"docvalues,omitempty"`
}FieldMapping不会再包含任何上述结构了,它是整个IndexMapping的叶节点。它的成员大多是bool型,其他string类型的变量也大多是描述作用。
- Type:描述该字段是作为那种类型,文本、数字、布尔、日期、地理坐标等。
- Store:该字段是否被存入索引。
- Index:该字段是否被索引。
- IncludeTermVectors:该字段的occ是否被保存,用于标红、短语query。
- IncludeInAll:该字段是否包含在all字段里,默认所有字段都在all字段,除非明确指定不包含。
- Analyzer:该字段使用哪种Analyzer。
2 实践落地
上一篇文章中建立新索引的代码,只包含了2个函数调用,代码重复如下。
indexMapping := bleve.NewIndexMapping()
index, err := bleve.New("example.bleve", mapping)为了指定各字段的索引方式,我们需要在初始化indexMapping后对其进行一些编辑修改。
blogMapping := bleve.NewDocumentMapping()
indexMapping.AddDocumentMapping("blog", blogMapping)上面的代码,在indexMapping新增加了一个文档类型blog,并为其建立了一个DocumentMapping。此时的DocumentMapping是空的,是默认方式。
nameFieldMapping := bleve.NewTextFieldMapping()
nameFieldMapping.Analyzer = "en"
blogMapping.AddFieldMappingsAt("name", nameFieldMapping)
CSS 复制 全屏上面的代码为blog类型的文本的name字段,添加了一个FieldMapping,并将其Analyzer指定为“en”。
注意:在1.2.1节中,我们提到了当DocumentMapping对应于文档或嵌入文档时,它不能包含FieldMapping。这里调用方法
blogMapping.AddFieldMappingsAt("name", nameFieldMapping),相当于为blogMapping在Properties成员上添加了一个key为"name"的DocumentMapping,再将nameFieldMapping这个FieldMapping添加到这个中间DocumentMapping的Fields。
author := bleve.NewDocumentMapping()
authorNameFieldMapping := bleve.NewTextFieldMapping()
authorNameFieldMapping.Store = false
author.AddFieldMappingsAt("name", authorFieldNameMapping)
authorEmailFieldMapping := bleve.NewTextFieldMapping()
authorEmailFieldMapping.IncludeInAll = false
author.AddFieldMappingsAt("email", authorEmailFieldMapping)
blog.AddSubDocumentMapping("author", author)上面的代码演示了如何在blog类型的DocumentMapping上添加一个嵌入文档的DocumentMapping。该嵌入文档在文档的key为author,包含name、email两个成员。并且,name只索引不存储,email不包含在_all字段。

smarteng
人生就流星,虽然转瞬即逝,但也有永恒。
- 使用Erlang的OTP框架创建应用
- php 使用curl模拟登录discuz以及模拟发帖
- 腾讯QQ、阿里旺旺、淘宝、MSN在线状态代码生成
- 新浪微博错误代码解析
- erlang程序设计笔记
- 《HTML 5与CSS 3权威指南》权威的HTML5与CSS3实战教程
- dedecms修改数据库密码配置文件
- 服务器优化小记--Etag和Expires
- Mediawiki的配置和修改方法
- 在PHP5中使用PHPMailer发送邮件
- PHP中冒号、endif、endwhile、endfor介绍
- PHP框架——ThinkPHP
- 使用Golang的官方mock工具--gomock、mockgen
- MacOs 电脑关闭/打开IPV6
- QQ登陆成功返回openId后与网站绑定
- MacOs 电脑关闭/打开IPV6
- MySQL中datetime和timestamp的区别
- C++声明结构
- 如何保证数据库和缓存的一致性
- 优雅的golang日期时间处理库go-carbon
- API接口纪要
- 解析 Golang 测试(11)- 模糊测试
- 解析 Golang 测试(10)- 什么是好的单测
- 解析 Golang 测试(9)- 一篇文章搞懂 testify
- 解析 Golang 测试(8)- gomonkey 实战
- 解析 Golang 测试(7)- 如何针对 Redis 进行 Fake 测试
- 解析 Golang 测试(6)- 如何针对 MySQL 进行 Fake 测试
- 解析 Golang 测试(5)- MySQL 经典 mock driver—— sqlmock
- 解析 Golang 测试(4)- 一篇文章教你分清 Mock,Stub,Fake
- 解析 Golang 测试(3)- goconvey 实战
- 2023年11月(1)
- 2023年10月(1)
- 2023年3月(2)
- 2023年2月(1)
- 2022年12月(1)
- 2022年9月(13)
- 2022年8月(5)
- 2022年7月(9)
- 2022年6月(2)
- 2022年5月(2)
- 2022年4月(1)
- 2022年3月(2)
- 2021年12月(1)
- 2021年11月(14)
- 2021年10月(2)
- 2021年9月(111)
- 2015年3月(1)
- 2014年5月(4)
- 2014年4月(18)
- 2014年1月(1)
- 2013年11月(2)
- 2013年7月(1)
- 2013年6月(1)
- 2013年3月(13)
- 2013年2月(3)
- 2013年1月(1)
- 2012年12月(8)
- 2012年11月(8)
- 2012年10月(1)
- 2012年9月(13)
- 2012年8月(4)
- 2012年6月(2)
- 2012年5月(10)
- 2012年4月(13)
- 2012年3月(9)
- 2012年2月(8)
- 2011年11月(1)
- 2011年8月(9)
- 2011年7月(8)
- 2011年6月(8)
- 2011年5月(7)
- 2011年4月(19)
- 2011年3月(15)
- 2011年2月(8)
- 2011年1月(9)
- 2010年12月(2)
- 2010年11月(2)
- 2010年10月(2)
- 2010年9月(8)
- 2010年8月(9)
- 2010年7月(1)
- 2010年6月(9)
- 2010年5月(5)
- 2010年1月(7)
- 2009年12月(21)
- 2009年11月(29)
- 2009年10月(100)
- 2009年8月(1)
- 2009年7月(15)
- 2009年6月(52)